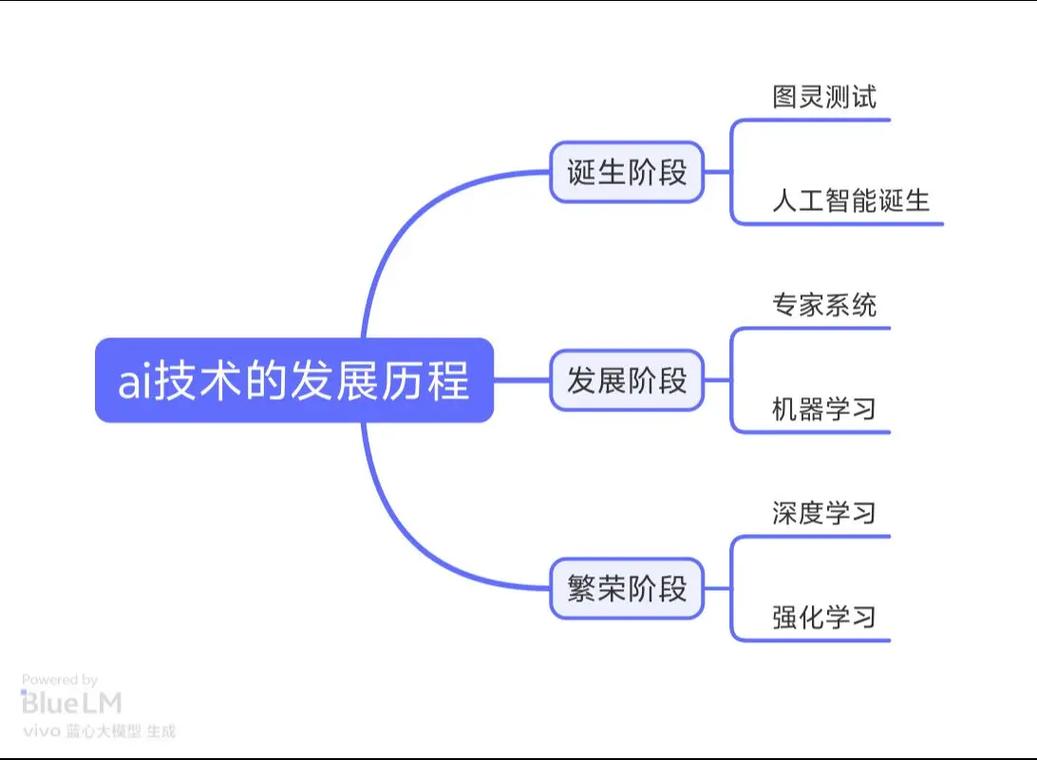
理论基础:AI的“大脑”和“灵魂”
理论基础为AI提供了思想、框架和目标,决定了AI“能思考什么”以及“如何思考”,它主要包括数学、计算机科学和认知科学。
数学基础
数学是AI的通用语言,为AI模型提供了描述和解决问题的工具。
- 线性代数:是现代AI的基石,神经网络中的所有运算,从数据表示(向量、矩阵)到层与层之间的变换(矩阵乘法),本质上都是线性代数运算,理解向量空间、矩阵运算、特征值等概念对于理解模型至关重要。
- 微积分:特别是梯度下降算法,AI模型通过不断调整内部参数来学习,而梯度下降就是指导如何调整这些参数的核心算法,它通过计算损失函数对参数的梯度(导数),找到使模型误差最小的方向。
- 概率论与统计学:AI的核心是从数据中学习规律,而概率与统计提供了量化不确定性和进行推断的框架,贝叶斯定理用于处理不确定性,最大似然估计用于模型训练,概率图模型用于处理复杂依赖关系。
- 信息论:提供了衡量信息、熵和不确定性的工具,交叉熵损失函数在分类任务中被广泛使用,它衡量了模型预测分布与真实分布之间的“距离”。
计算机科学基础
计算机科学提供了实现AI理论和算法的工具与环境。
- 形式逻辑与自动推理:这是AI早期的方向,致力于让机器像人类一样进行逻辑推理,虽然它不再是当前AI的主流,但其思想(如知识表示、搜索算法)仍然在专家系统、规划等领域有应用。
- 计算复杂性理论:帮助理解哪些问题是计算机可以有效解决的(P类问题),哪些问题是难以解决的(NP类问题),这为AI算法的设计提供了理论边界。
- 数据结构与算法:高效的算法(如搜索、排序、图算法)是处理大规模数据、优化模型性能的基础。
认知科学基础
认知科学试图理解人类的智能和思维过程,为AI提供了重要的灵感来源。
- 认知心理学:研究人类的感知、学习、记忆和决策过程,深度学习中的“层次化”结构就受到了人类视觉皮层处理信息的启发。
- 语言学:特别是乔姆斯基的形式语言学,对早期自然语言处理产生了深远影响,现代的Transformer模型也借鉴了人类在处理语言时的注意力机制。
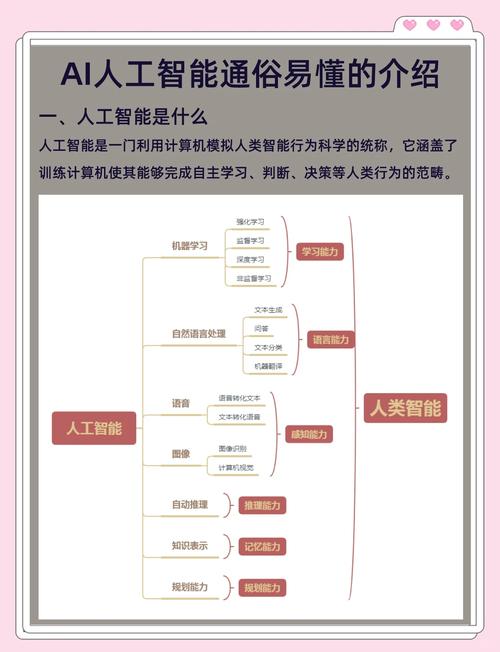
数据基础:AI的“燃料”
如果说算法是引擎,那么数据就是驱动引擎的燃料,没有高质量、大规模的数据,再先进的算法也无法发挥威力。
数据的规模
AI模型,尤其是深度学习模型,具有数百万甚至数十亿个参数,要训练如此复杂的模型,需要海量的数据来覆盖各种场景,避免模型“过拟合”(只记住训练数据中的特例,无法泛化到新数据),互联网的普及和数字化进程产生了前所未有的海量数据,这是AI爆发式增长的前提。
数据的质量与多样性
“Garbage in, garbage out.”(垃圾进,垃圾出),数据的质量直接影响模型的性能,数据需要准确、无偏见、具有代表性,数据的多样性(不同场景、不同角度、不同人群的数据)能帮助模型学习到更鲁棒、更通用的特征,而不是片面的知识。
数据的获取与处理
- 公开数据集:ImageNet(图像识别)、COCO(目标检测)、SQuAD(问答)等高质量、大规模的公开数据集,为研究者提供了公平的基准,极大地推动了AI领域的发展。
- 数据标注:监督学习需要大量带标签的数据(如“猫”的图片需要被标记为“猫”),众包平台和专业的数据标注公司为此提供了支持,但这也是一个成本高昂且耗时的过程。
- 数据存储与管理:分布式文件系统(如HDFS)和数据库技术(如NoSQL)使得存储和处理PB(10¹⁵字节)级别的海量数据成为可能。
算力基础:AI的“引擎”
复杂的AI模型需要强大的计算能力才能在合理的时间内完成训练,算力的突破直接决定了AI能走多远。
硬件革命
- GPU(图形处理器):这是现代AI的“功臣”,与CPU专为串行任务设计不同,GPU拥有数千个核心,擅长并行计算,这与神经网络中大量矩阵运算的需求完美匹配,NVIDIA的GPU成为了深度学习研究的标配。
- TPU(张量处理器):Google专为AI设计的ASIC(专用集成电路),针对张量运算进行了高度优化,在训练和推理某些模型时比GPU更高效、更节能。
- FPGA(现场可编程门阵列):提供了硬件级别的可定制性,在某些特定场景下能提供能效比优势。
计算架构创新
- 云计算:AWS、Google Cloud、Azure等云平台提供了按需分配的弹性计算资源,使得研究机构和中小企业也能以较低的成本获取强大的算力,极大地降低了AI技术的门槛。
- 分布式计算:将一个巨大的训练任务分解到成千上万个计算节点上并行处理,使得训练像GPT-3这样拥有数千亿参数的“巨无霸”模型成为可能。
算法基础:AI的“核心技能”
算法是AI的灵魂,它定义了模型如何从数据中学习,如何进行推理和决策,算法的迭代是AI性能飞跃的直接原因。
机器学习算法的演进
- 早期阶段(1950s-1980s):以符号主义为主,如专家系统、决策树,这些方法依赖于人工编写的规则,泛化能力差。
- 统计学习时代(1980s-2010s):以连接主义和统计学习为主。支持向量机、贝叶斯网络、隐马尔可夫模型等算法在特定任务上取得了巨大成功,但它们通常需要人工设计特征,泛化能力有限。
- 深度学习革命(2010s-至今):这是当前AI的主流范式。
- 关键突破:反向传播算法:它解决了如何高效训练多层神经网络的问题,是深度学习的核心。
- 关键突破:激活函数:如ReLU解决了深层网络的梯度消失问题,让深层网络成为可能。
- 关键突破:卷积神经网络:通过卷积和池化操作,自动学习图像的层次化特征,在图像识别领域取得革命性突破(如AlexNet在ImageNet上的胜利)。
- 关键突破:循环神经网络 与 LSTM/GRU:专为处理序列数据(如文本、语音)设计,在自然语言处理和语音识别中表现出色。
- 关键突破:Transformer 与注意力机制:彻底改变了NLP领域,通过“自注意力机制”,模型能够捕捉句子中长距离的依赖关系,并行计算效率高,BERT、GPT等基于Transformer的模型开启了大语言模型时代。
强化学习
除了监督学习,强化学习也是AI的重要分支,它通过与环境的交互,通过“试错”和“奖励”信号来学习最优策略,AlphaGo战胜李世石就是强化学习结合深度学习的典范之作。
四大基础的协同演进
人工智能技术的发展并非源于单一领域的突破,而是这四大基础协同演进、相互促进的结果:
- 理论指明了方向(“我们想造什么样的智能?”)。
- 数据提供了学习的原材料(“用什么来教它?”)。
- 算力提供了实现的工具(“用什么来造它?”)。
- 算法提供了实现的具体方法(“具体怎么教?”)。
深度学习的崛起就是最好的证明: 反向传播算法(算法)的成熟,加上GPU(算力)的普及,使得我们能够高效训练深度神经网络(理论),而互联网产生的海量图像数据(数据),则为训练强大的CNN模型提供了可能,最终引爆了计算机视觉的革命。
这四大基础仍在不断深化发展,新的理论(如神经符号AI)、更高质量的数据、更强大的算力(如专用AI芯片)以及更高效的算法(如更高效的注意力机制)正在推动人工智能向着更通用、更可靠、更安全的未来迈进。


