这是一个非常常见的需求,但实现起来需要一点技巧,因为 iptables 主要工作在网络层(L3)和传输层(L4),它直接看到的是 IP 地址、端口和协议,而 URL 及其参数是应用层(L7)的数据。
我们不能直接告诉 iptables "过滤掉 ?id=123",我们需要一个“代理”或“中间人”来读取应用层数据,然后告诉 iptables 是否应该丢弃这个数据包。
下面我将介绍两种主要的方法,并给出详细的配置步骤和优缺点分析。
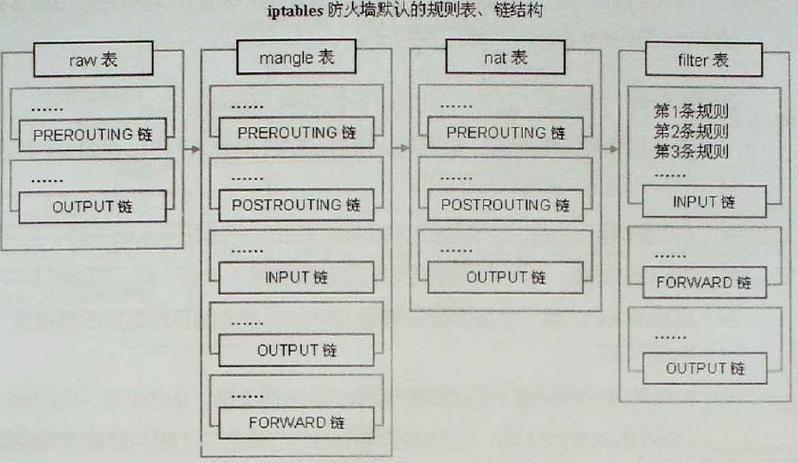
使用 iptables + string 模块(不推荐,但有教育意义)
iptables 本身有一个 string 模块,可以扫描数据包负载(Payload)中的特定字符串,理论上,我们可以用它来匹配 URL 参数。
工作原理:
iptables 会检查 TCP 数据包中的实际数据内容,如果包含了我们指定的字符串,就执行相应的动作(如 DROP)。
示例:
假设我们有一个运行在 80 端口的 Web 服务器,我们想丢弃所有请求中包含 ?malicious_param= 的数据包。
# 1. 创建一个新的链,URL_FILTER iptables -N URL_FILTER # 2. 将进入本机 80 端口的 TCP 数据包跳转到我们的新链 iptables -A INPUT -p tcp --dport 80 -j URL_FILTER # 3. 在新链中,使用 string 模块匹配并丢弃包含恶意参数的数据包 # --string: 要匹配的字符串 # --algo: 匹配算法,bm (Boyer-Moore) 通常更快 # -j DROP: 匹配到则丢弃数据包 iptables -A URL_FILTER -p tcp --dport 80 --string "?malicious_param=" --algo bm -j DROP # 4. 允许其他所有正常流量通过 iptables -A URL_FILTER -j ACCEPT
为什么这种方法不推荐?
- 性能极差:
iptables需要检查每一个进入 80 端口的数据包的完整内容,对于 HTTPS 流量,内容是加密的,这种方法完全无效,即使对于 HTTP,这也会给服务器带来巨大的 CPU 负担,严重影响性能。 - 误报率高:URL 参数可能会出现在任何地方,POST 请求的
body中、Referer头中、甚至 JavaScript 文件里,你可能会误杀大量合法的流量。 - 不安全:
iptables运行在内核态,直接操作网络数据包,这种深度包检测(DPI)方式容易导致系统不稳定。 - 无法处理加密流量:如前所述,HTTPS 流量是加密的,
iptables无法读取其内容。
这种方法仅用于学习和测试,绝对不要在生产环境中使用。
使用 iptables + NFQUEUE(推荐的专业方法)
这是目前最灵活、最强大的方法,也是专业解决方案(如 WAF - Web Application Firewall)的基础。
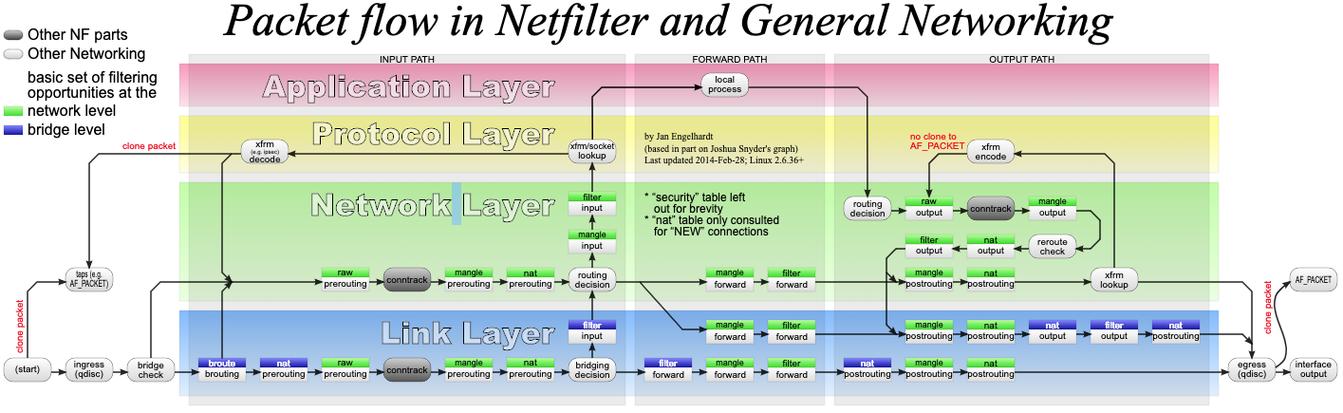
工作原理:
iptables 不再亲自处理数据,而是扮演一个“交通警察”的角色,当它看到一个符合条件的数据包时,它不会直接 DROP 或 ACCEPT,而是将这个数据包的“处理权”转交给一个用户空间(User-space)的程序,这个程序可以是一个用 Python、C、Go 等语言编写的脚本,它负责解包、分析 URL 参数,然后做出最终决策(允许、拒绝、记录日志等),最后将决定返回给内核的 iptables。
核心组件:
iptables:负责捕获数据包并将其放入一个NFQUEUE队列。libnetfilter_queue:一个用户空间的库,允许程序从内核的NFQUEUE中接收数据包。- 一个用户空间脚本:例如一个 Python 脚本,使用
libnetfilter_queue库来处理数据包。
实施步骤:
第 1 步:安装必要的工具
你需要安装 iptables 和用于处理 NFQUEUE 的工具包,python-nfqueue。
# 对于 Debian/Ubuntu sudo apt-get update sudo apt-get install iptables libnfnetlink-dev libnetfilter-queue-dev # 安装 Python 的 NFQUEUE 绑定 sudo pip install nfqueue
第 2 步:编写用户空间处理脚本(Python 示例)
创建一个名为 url_filter.py 的文件。
#!/usr/bin/env python3
import nfqueue
import socket
from urllib.parse import urlparse, parse_qs
# 定义要过滤的参数和值
BLOCKED_PARAMS = {
'id': ['123', '456'], # 阻止所有包含 id=123 或 id=456 的请求
'debug': ['true'], # 阻止所有包含 debug=true 的请求
}
def process_packet(payload):
"""
这是核心的处理函数,当有数据包进入队列时被调用。
"""
try:
# 获取数据包
data = payload.get_data()
# 创建一个 NFQUEUE 元素对象,用于返回决定给内核
payload.set_verdict(nfqueue.NF_DROP) # 默认先丢弃,除非我们明确允许
# 解析 IP 和 TCP 头
# 注意:这里我们只处理 HTTP,并且假设是 GET 请求
# 实际应用中需要更复杂的解析逻辑
# 简单地查找 HTTP GET 请求行
if b'GET ' not in data:
payload.set_verdict(nfqueue.NF_ACCEPT) # 如果不是 GET 请求,允许通过
return
# 提取 URL 部分 (简化版)
start = data.find(b'GET ') + 4
end = data.find(b' HTTP/1.')
if start == -1 or end == -1:
payload.set_verdict(nfqueue.NF_ACCEPT) # 格式不对,允许通过
return
url_bytes = data[start:end]
url = url_bytes.decode('utf-8', errors='ignore')
# 解析 URL 参数
parsed_url = urlparse(url)
query_params = parse_qs(parsed_url.query)
# 检查参数是否在黑名单中
for param, values in BLOCKED_PARAMS.items():
if param in query_params:
for v in values:
if v in query_params[param]:
print(f"BLOCKED: Found blocked parameter '{param}={v}' in URL: {url}")
# 找到匹配项,设置决定为丢弃,并返回
payload.set_verdict(nfqueue.NF_DROP)
return
# 如果所有检查都通过,则允许数据包通过
payload.set_verdict(nfqueue.NF_ACCEPT)
except Exception as e:
print(f"Error processing packet: {e}")
# 出错时,为了安全起见,丢弃数据包
payload.set_verdict(nfqueue.NF_DROP)
def main():
# 创建一个队列处理器
queue = nfqueue.queue()
queue.open()
queue.bind(socket.AF_INET) # 绑定到 IPv4
queue.set_callback(process_packet)
queue.add_queue(0) # 使用队列号 0
print("URL Filter is running. Press Ctrl+C to stop.")
try:
queue.loop()
except KeyboardInterrupt:
print("\nStopping URL Filter...")
finally:
queue.unbind(socket.AF_INET)
queue.close()
if __name__ == '__main__':
main()
第 3 步:配置 iptables 规则
我们配置 iptables,将需要过滤的流量(发往本机 80 端口的流量)重定向到 NFQUEUE。
# 1. 清空所有可能冲突的规则(谨慎操作!) # iptables -F # iptables -X # 2. 创建一个新的链 iptables -N NFQ_URL_FILTER # 3. 将进入本机 80 端口的 TCP 流量跳转到新链 iptables -A INPUT -p tcp --dport 80 -j NFQ_URL_FILTER # 4. 在新链中,将流量重定向到 NFQUEUE # --queue-num: 指定队列号,必须与 Python 脚本中的 add_queue(0) 对应 # --queue-bypass: 如果没有用户空间程序在监听队列,允许数据包通过(避免网络中断) iptables -A NFQ_URL_FILTER -p tcp --dport 80 -j NFQUEUE --queue-num 0 --queue-bypass # 5. 允许其他所有流量 iptables -A NFQ_URL_FILTER -j ACCEPT
第 4 步:运行脚本并测试
-
给 Python 脚本执行权限:
chmod +x url_filter.py
-
在一个终端中运行脚本(需要
root权限):sudo python3 url_filter.py
你会看到 "URL Filter is running..." 的提示。
-
在另一个终端中,使用
curl或浏览器测试:# 这个应该被允许 curl http://your-server-ip/index.html # 这个应该被脚本拦截并在终端打印日志 curl "http://your-server-ip/index.html?id=123" # 这个也应该被拦截 curl "http://your-server-api.com/data?debug=true"
方法二的优点:
- 功能强大:可以做任何应用层能做的事情,包括深度协议分析、内容过滤、与数据库交互等。
- 性能可控:复杂的逻辑在用户空间处理,内核只负责高速转发数据包到队列,性能瓶颈在用户程序,但可以优化。
- 灵活:可以轻松修改 Python 脚本来改变过滤规则,而无需重新编译内核或重启
iptables。 - 可扩展:可以集成到复杂的 WAF 系统中。
更简单、更推荐的生产环境方案:使用成熟的 Web 服务器或 WAF
对于绝大多数场景,直接修改 iptables 或自己写 NFQUEUE 脚本都是“杀鸡用牛刀”,而且容易出错,更简单、更安全、更高效的做法是利用已有的工具:
使用 Web 服务器自身的模块
-
Nginx: 使用
ngx_http_if_module和map指令。# 在 http, server, 或 location 块中配置 map $args $block_request { default 0; "~id=(123|456)" 1; # 如果参数 id 是 123 或 456,则 $block_request 为 1 "~debug=true" 1; } server { # ... 其他配置 ... if ($block_request) { return 403 "Forbidden: Blocked parameter detected."; } # ... } -
Apache: 使用
mod_rewrite。RewriteEngine On # 检查查询字符串 RewriteCond %{QUERY_STRING} (^|&)id=(123|456)(&|$) RewriteRule ^ - [F] # F = Forbidden (403) RewriteCond %{QUERY_STRING} (^|&)debug=true(&|$) RewriteRule ^ - [F]
使用专业的 Web 应用防火墙
- ModSecurity: 一个功能极其强大的开源 WAF,可以集成到 Nginx 或 Apache 中,它使用强大的规则集(如 OWASP ModSecurity Core Rule Set)来保护你的应用。
- 云服务商的 WAF: 如 AWS WAF, Google Cloud Armor, Azure Front Door 等,它们提供可视化的管理界面和预定义的规则集,无需关心底层实现。
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
iptables + string |
简单,无需额外程序 | 性能极差,不安全,不处理加密 | 学习、测试,不推荐生产 |
iptables + NFQUEUE |
功能强大,灵活,可定制 | 实现复杂,需要编程,性能依赖用户程序 | 需要深度包检测和自定义逻辑的专家级应用 |
| Web 服务器模块 | 简单,高效,与服务器集成 | 功能相对固定 | 大多数 Web 应用的基本参数过滤需求 |
| 专业 WAF | 功能最全,规则丰富,性能好,有社区支持 | 可能需要付费,配置有一定学习成本 | 生产环境,对安全性要求高的任何 Web 应用 |
最终建议:
- 如果你只是想过滤 URL 参数,请优先使用 Nginx 或 Apache 的内置模块,这是最简单、最可靠的方式。
- 如果你需要构建一个复杂的、自定义的 Web 应用防火墙,
iptables+NFQUEUE是一个强大的技术路线。 - 如果你追求最高级别的安全性和易用性,请直接使用 ModSecurity 或 云服务商的 WAF。


