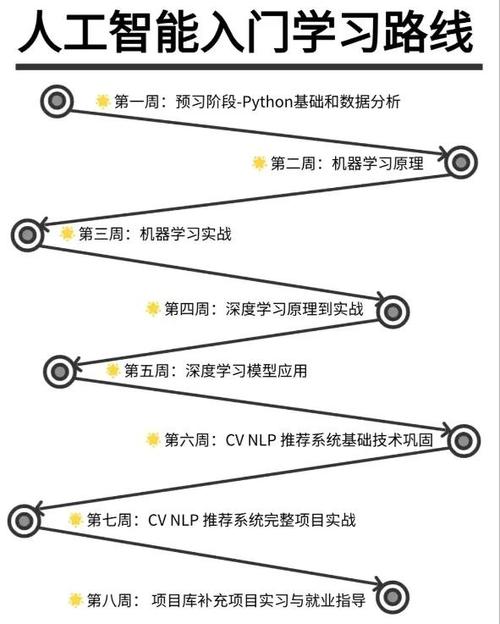
Python 人工智能学习路线图
这条路线图分为六个阶段,你可以根据自己的节奏逐步完成:
(图片来源网络,侵删)
- 第一阶段:Python 基础与核心库
- 第二阶段:人工智能与机器学习基础
- 第三阶段:经典机器学习算法
- 第四阶段:深度学习入门
- 第五阶段:专业领域与前沿技术
- 第六阶段:项目实战与持续学习
第一阶段:Python 基础与核心库
在进入 AI 之前,你必须熟练掌握 Python,因为它是 AI 领域的“普通话”。
Python 基础语法
- 变量与数据类型: 整数、浮点数、字符串、布尔值。
- 数据结构: 列表、元组、字典、集合,这是 Python 的核心,必须精通。
- 控制流:
if-else条件语句,for和while循环。 - 函数: 定义函数、参数传递、返回值。
- 面向对象编程: 类、对象、继承、封装,理解 OOP 对编写大型 AI 项目至关重要。
- 模块与包:
import语句,如何使用和创建自己的模块。
推荐资源:
- 教程: 廖雪峰的 Python 教程, 菜鸟教程
- 书籍: 《Python 编程:从入门到实践》
- 练习: LeetCode (先做简单题), HackerRank
科学计算与数据处理三巨头
这是 AI 数据处理和实验的基石。
-
NumPy (Numerical Python)
 (图片来源网络,侵删)
(图片来源网络,侵删)- 作用: 高性能的多维数组对象(
ndarray),用于进行数学、逻辑、形状操作、排序、选择、I/O、离散傅里叶变换、基本线性代数等。 - 核心概念: 数组创建、索引、切片、广播、数学运算。
- 学习目标: 能够用 NumPy 高效地处理和操作数值数据。
- 作用: 高性能的多维数组对象(
-
Pandas (Python Data Analysis Library)
- 作用: 提供了高性能、易于使用的数据结构(
Series和DataFrame),用于数据清洗、转换、分析和可视化。 - 核心概念:
DataFrame的创建与索引、数据筛选、缺失值处理、分组聚合、时间序列。 - 学习目标: 能够像使用 Excel 一样处理和分析表格数据,这是数据科学家的日常。
- 作用: 提供了高性能、易于使用的数据结构(
-
Matplotlib & Seaborn
- 作用: 数据可视化库,Matplotlib 是基础,Seaborn 基于 Matplotlib 提供了更美观、更高级的统计图表。
- 核心概念: 绘制折线图、散点图、柱状图、直方图、箱线图等。
- 学习目标: 能够通过可视化来理解数据分布、特征关系和模型结果。
推荐资源:
- 教程: NumPy 官方教程, Pandas 官方文档
- 课程: Coursera 上的 "Python for Data Science and AI" 专项课程。
第二阶段:人工智能与机器学习基础
我们开始进入 AI 的核心概念。

(图片来源网络,侵删)
什么是人工智能、机器学习和深度学习?
- 人工智能: 一个宽泛的科学领域,目标是让机器像人一样思考和行动。
- 机器学习: AI 的一个子集,让计算机通过数据学习,而不是通过显式编程。
- 深度学习: 机器学习的一个子集,使用多层神经网络来学习数据的复杂模式。
机器学习工作流程
- 数据收集与准备: 获取数据,清洗数据(处理缺失值、异常值)。
- 特征工程: 从原始数据中提取对模型有用的特征。
- 模型选择: 根据问题类型选择合适的算法。
- 模型训练: 用训练数据“喂”给模型,让它学习规律。
- 模型评估: 用测试数据评估模型的性能(准确率、精确率、召回率等)。
- 模型调优: 调整参数,优化模型性能。
- 模型部署: 将训练好的模型应用到实际场景中。
监督学习 vs. 无监督学习
- 监督学习: 数据带有“标签”(答案),目标是学习一个从输入到输出的映射。
- 分类问题: 输出是离散的类别(如:垃圾邮件/非垃圾邮件)。
- 回归问题: 输出是连续的数值(如:房价预测)。
- 无监督学习: 数据没有标签,目标是发现数据内在的结构和模式。
- 聚类问题: 将相似的数据点分到一组(如:客户分群)。
- 降维问题: 减少数据的特征数量,同时保留主要信息(如:数据可视化)。
推荐资源:
- 书籍: 《机器学习》(周志华,俗称“西瓜书”) - 理论较深,适合后续深入。
- 视频: 3Blue1Brown 的《机器学习本质》系列视频 - 直观理解核心概念。
- 课程: Andrew Ng 的 Machine Learning Specialization (新版,Python版) 或 经典版 (Matlab/Octave版,但理论经典)。
第三阶段:经典机器学习算法
使用 Python 最流行的机器学习库 Scikit-learn 来实践。
Scikit-learn 简介
- 作用: 提供了简单高效的工具用于数据挖掘和数据分析,它封装了几乎所有经典机器学习算法。
- 核心流程:
数据准备 -> 初始化模型 -> model.fit(X_train, y_train) -> model.predict(X_test) -> 评估结果。
必学算法
- 线性回归: 回归问题的入门算法。
- 逻辑回归: 分类问题的入门算法。
- K-近邻: 简单的、基于实例的算法。
- 支持向量机: 强大的分类和回归算法。
- 决策树 & 随机森林: 非常流行的集成学习算法,可解释性强。
- K-Means 聚类: 无监督学习的入门聚类算法。
- 主成分分析: 经典的降维算法。
推荐资源:
- 教程: Scikit-learn 官方文档 是最好的学习材料,配有大量示例。
- 实践: 在 Kaggle 上找一些入门竞赛(如 Titanic: Machine Learning from Disaster),用学到的算法尝试解决。
第四阶段:深度学习入门
当数据复杂(如图像、语音、文本)时,深度学习大显身手。
核心概念
- 神经元: 深度学习的基本单元。
- 神经网络: 由多层神经元连接而成的网络。
- 激活函数: 为网络引入非线性,如
ReLU,Sigmoid,Tanh。 - 反向传播: 神经网络的核心学习算法,通过计算梯度来更新权重。
- 损失函数: 衡量模型预测值与真实值差距的函数。
- 优化器: 用于更新模型权重的算法,如
SGD,Adam。
深度学习框架
选择一个框架并深入学习。PyTorch 目前在学术界和工业界都非常流行,推荐初学者学习。
-
PyTorch
- 特点: 动态计算图,Pythonic,易于调试,社区活跃。
- 学习路径:
- 基础: 熟悉
Tensor(张量,类似于 NumPy 数组) 和autograd(自动求导)。 - 构建网络: 学习使用
torch.nn.Module来定义自己的模型。 - 训练循环: 掌握数据加载、模型训练、验证和测试的标准流程。
- 基础: 熟悉
-
TensorFlow / Keras
- 特点: 生态系统强大,工业部署支持好,Keras 是其高级 API,简洁易用。
- 学习路径: 从 Keras 开始,可以快速搭建和训练模型,再深入了解 TensorFlow。
经典网络模型
- 卷积神经网络: 专门用于处理图像数据。
- 核心组件: 卷积层、池化层。
- 应用: 图像分类、目标检测。
- 循环神经网络: 专门用于处理序列数据(如文本、时间序列)。
- 核心组件: LSTM, GRU (解决了 RNN 的长期依赖问题)。
- 应用: 机器翻译、情感分析、文本生成。
推荐资源:
- 课程: Stanford University 的 CS231n (Convolutional Neural Networks for Visual Recognition) 和 CS224n (Natural Language Processing with Deep Learning),课程视频和笔记可以在网上找到。
- 书籍: 《深度学习》(花书)- 理论非常全面。
- 实践: 在 PyTorch 官方教程中找到 "60 Minute Blitz" 快速上手。
第五阶段:专业领域与前沿技术
在掌握了基础后,可以根据兴趣选择一个方向深入。
- 计算机视觉: 目标检测、图像分割、人脸识别、生成对抗网络。
- 自然语言处理: 文本分类、命名实体识别、机器翻译、大型语言模型。
- 强化学习: 让智能体通过与环境交互来学习最优策略(如 AlphaGo)。
- 生成式 AI: GANs, Diffusion Models (如 Stable Diffusion), 大型语言模型 (如 GPT 系列)。
推荐资源:
- Hugging Face: NLP 领域的“瑞士军刀”,提供了大量预训练模型和工具库,是学习现代 NLP 的必备。
- Papers with Code: 一个跟踪最新 AI 研究和开源实现的网站。
第六阶段:项目实战与持续学习
理论学得再多,不如亲手做一个项目。
项目想法(从易到难)
- 入门级:
- 手写数字识别 (MNIST 数据集)。
- 电影评论情感分析。
- 泰坦尼克号生还者预测。
- 进阶级:
- 猫狗图像分类。
- 使用 OpenCV 进行人脸检测。
- 构建一个简单的聊天机器人。
- 高级:
- 目标检测项目(如 YOLO)。
- 使用 GAN 生成人脸图像。
- 微调一个大型语言模型(如 BERT)来完成特定任务。
持续学习
AI 领域日新月异,保持学习至关重要。
- 关注社区: arXiv (阅读最新论文), Reddit (r/MachineLearning), Twitter 关注 AI 大牛。
- 参加竞赛: Kaggle 是最好的实践平台。
- 阅读源码: 阅读优秀开源项目的代码,学习最佳实践。
- 写博客/做分享: 教是最好的学,通过输出巩固自己的知识。
总结与建议
- 不要急于求成: AI 知识体系庞大,打好 Python 和数学基础(线性代数、概率论、微积分)至关重要。
- 动手实践: 每学一个新概念,都尝试用代码实现它,多写代码,多调 Bug。
- 理论与实践结合: 既要理解算法背后的数学原理,也要会用库快速实现。
- 选择一个主攻方向: 在广泛了解后,选择一个你感兴趣的领域(CV, NLP, RL 等)进行深耕。
祝你学习顺利,早日成为 AI 大神!


