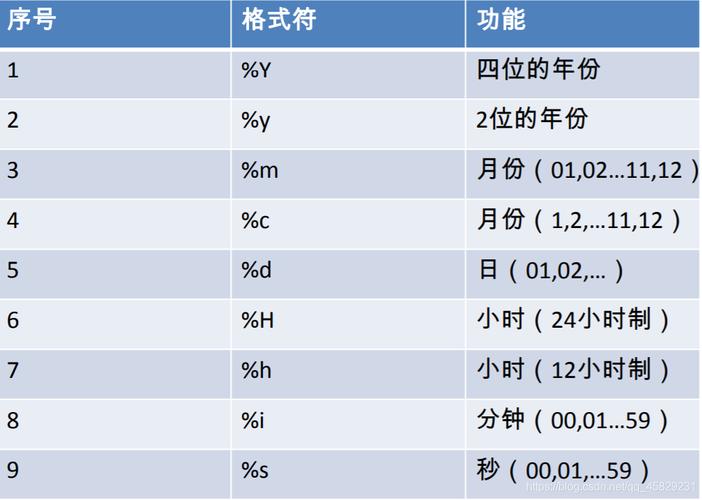
INSTR() 函数用于返回一个子字符串在另一个字符串中第一次出现的位置。
(图片来源网络,侵删)
基本语法:
INSTR(str, substr)
参数详解
INSTR 函数接受两个主要参数,这两个参数都是必需的。
参数 1: str (被搜索的字符串)
- 类型:
String(字符串) - 描述: 这是您要在其中进行搜索的原始字符串或字符串表达式,它可以是字面量、表中的列名,或者任何可以解析为字符串的表达式。
- 示例:
'Hello, World!'user_email(假设user_email是一个包含电子邮件地址的列)CONCAT(first_name, ' ', last_name)(一个由多列拼接而成的字符串)
参数 2: substr (要查找的子字符串)
- 类型:
String(字符串) - 描述: 这是您要在
str中查找的目标子字符串,它同样可以是字面量、列名或字符串表达式。 - 示例:
'World'domain_name(假设domain_name是一个包含域名后缀的列)
返回值
INSTR 函数的返回值是一个整数,具体含义如下:
- 成功找到: 返回
substr在str中第一次出现的起始位置。位置计数从 1 开始,而不是从 0 开始。 - 未找到:
str中不包含substr,则返回0。 - 参数为 NULL: 如果任一参数 (
str或substr) 为NULL,则整个函数的返回值也为NULL。
使用示例
让我们通过一些实际的例子来更好地理解这个函数。
(图片来源网络,侵删)
示例 1: 基本用法
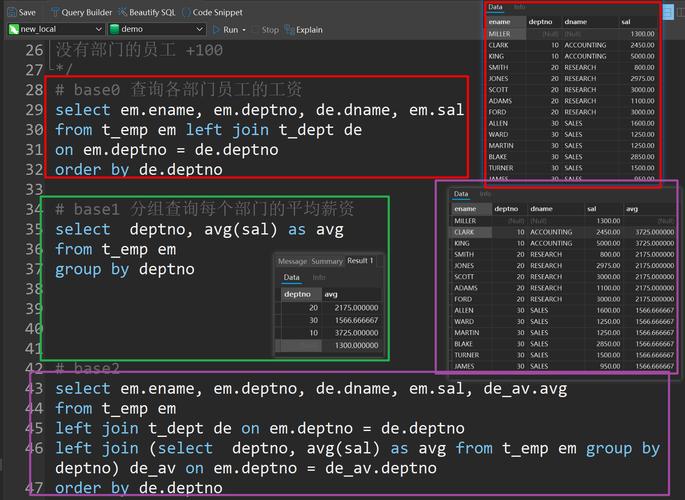
SELECT INSTR('Hello, World!', 'World');
结果:
8解释: 子字符串 'World' 在 'Hello, World!' 中从第 8 个字符开始。
示例 2: 未找到的情况
SELECT INSTR('Hello, World!', 'MySQL');
结果:
0解释: 因为 'Hello, World!' 中不包含 'MySQL',所以返回 0。
(图片来源网络,侵删)
示例 3: 查找单个字符
SELECT INSTR('example@email.com', '@');
结果:
8解释: 符号出现在第 8 个位置。
示例 4: 在表数据中使用
假设我们有一个 users 表,结构如下:
| id | username | |
|---|---|---|
| 1 | john_doe | john@example.com |
| 2 | jane_smith | jane@another.org |
| 3 | admin | admin@localhost |
场景: 找出所有 符号出现在域名部分( 之后)的第一个字符是 'o' 的用户。
SELECT
username,
email,
INSTR(email, '@') AS at_symbol_position
FROM
users
WHERE
INSTR(SUBSTRING(email, INSTR(email, '@') + 1), 'o') > 0;
查询分析:
INSTR(email, '@'): 找到 符号的位置。SUBSTRING(email, INSTR(email, '@') + 1): 从 符号的下一个字符开始截取字符串,得到域名部分('example.com','another.org')。INSTR(SUBSTRING(...), 'o'): 在截取出的域名部分查找字母'o'。... > 0: 如果找到,返回值会大于 0,WHERE条件成立。
结果: | username | email | at_symbol_position | |----------|--------------------|---------------------| | john_doe | john@example.com | 5 | | admin | admin@localhost | 6 |
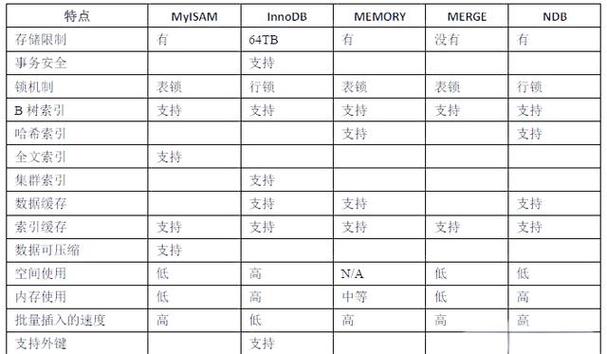
与 LOCATE 和 POSITION 的对比
在 MySQL 中,有多个函数可以实现类似的功能,了解它们的区别很重要。
| 函数 | 语法 | 区别 |
|---|---|---|
INSTR(str, substr) |
INSTR(str, substr) |
参数顺序是 (被搜索的字符串, 要找的子字符串),位置从 1 开始,这是最传统的写法。 |
LOCATE(substr, str) |
LOCATE(substr, str) |
参数顺序是 (要找的子字符串, 被搜索的字符串),这与 INSTR 相反,但功能相同,位置也从 1 开始。 |
POSITION(substr IN str) |
POSITION(substr IN str) |
语法更符合 SQL 标准,参数顺序与 LOCATE 相同,即 (要找的子字符串 IN 被搜索的字符串),位置也从 1 开始。 |
示例对比: 这三个查询的结果是完全一样的。
SELECT INSTR('Hello World', 'World'); -- 返回 7
SELECT LOCATE('World', 'Hello World'); -- 返回 7
SELECT POSITION('World' IN 'Hello World'); -- 返回 7
推荐:
LOCATE和POSITION的参数顺序 (find in) 在逻辑上更直观,因此更受推荐。INSTR也很常见,特别是在从其他数据库(如 Oracle)迁移过来的代码中。
性能考虑
对于简单的字符串查找,INSTR、LOCATE 和 POSITION 的性能差异可以忽略不计,但在处理非常大的字符串或进行大量数据查询时,需要注意:
- 索引: 如果您需要在
WHERE子句中频繁使用INSTR函数来搜索文本(WHERE INSTR(description, 'keyword') > 0),那么普通索引(B-Tree)通常无法被有效利用,数据库无法通过索引直接定位包含某个关键词的行。 - 全文索引: 对于在文本内容中搜索关键词的需求,MySQL 提供了全文索引(FULLTEXT Index),它在性能上远超
INSTR,并且支持更复杂的搜索逻辑(如布尔搜索、相关性评分等),如果您有全文搜索的需求,应优先考虑使用FULLTEXT索引和MATCH() ... AGAINST()语法。
| 特性 | 描述 |
|---|---|
| 函数名 | INSTR |
| 参数 | INSTR(str, substr) - str: (必需) 被搜索的字符串。 - substr: (必需) 要查找的子字符串。 |
| 返回值 | - 成功时,返回子串的起始位置(从 1 开始)。 - 失败时,返回 0。 - 任一参数为 NULL 时,返回 NULL。 |
| 大小写敏感 | 取决于数据库的排序规则,如果排序规则是区分大小写的(如 utf8mb4_bin),则区分大小写;否则不区分。 |
| 替代方案 | LOCATE(substr, str) 和 POSITION(substr IN str) 功能相同,但参数顺序更直观。 |
| 性能建议 | 用于简单查找,对于复杂的文本搜索,请使用 FULLTEXT 索引。 |


